在数字化时代,大数据已成为驱动商业洞察、科学研究和智能决策的核心燃料。原始数据如同未经雕琢的玉石,其价值的释放依赖于一套严谨、系统的处理流程。本文旨在详细拆解大数据处理的全过程,从最初的零起点到最终的结论验证,为读者勾勒出一条清晰的技术与实践路线图。
第一阶段:数据采集与获取
一切始于数据。数据来源极其多样,包括但不限于:
1. 业务系统日志:如网站点击流、应用程序日志。
2. 传感器与物联网设备:实时产生的海量物理世界数据。
3. 公开数据集与第三方数据:用于补充和丰富分析维度。
4. 社交媒体与公开网络:通过爬虫等技术获取的非结构化数据。
关键挑战在于确保数据采集的实时性、完整性和合法性,并设计高效的数据摄取管道,将数据从源头平稳地导入存储或处理平台。
第二阶段:数据存储与管理
采集到的数据需要被妥善存储和管理。根据数据结构和访问模式,存储方案通常分为:
- 大数据存储系统:如Hadoop HDFS(用于分布式文件存储)、NoSQL数据库(如HBase、Cassandra,适用于非结构化或半结构化数据)和云对象存储(如AWS S3)。
- 数据湖/数据仓库:数据湖存储原始、未经处理的数据;数据仓库则存储清洗、转换后的结构化数据,服务于分析查询。现代架构常采用湖仓一体模式。
管理的核心是元数据管理、数据目录和数据安全策略,确保数据可发现、可理解、可信任且受保护。
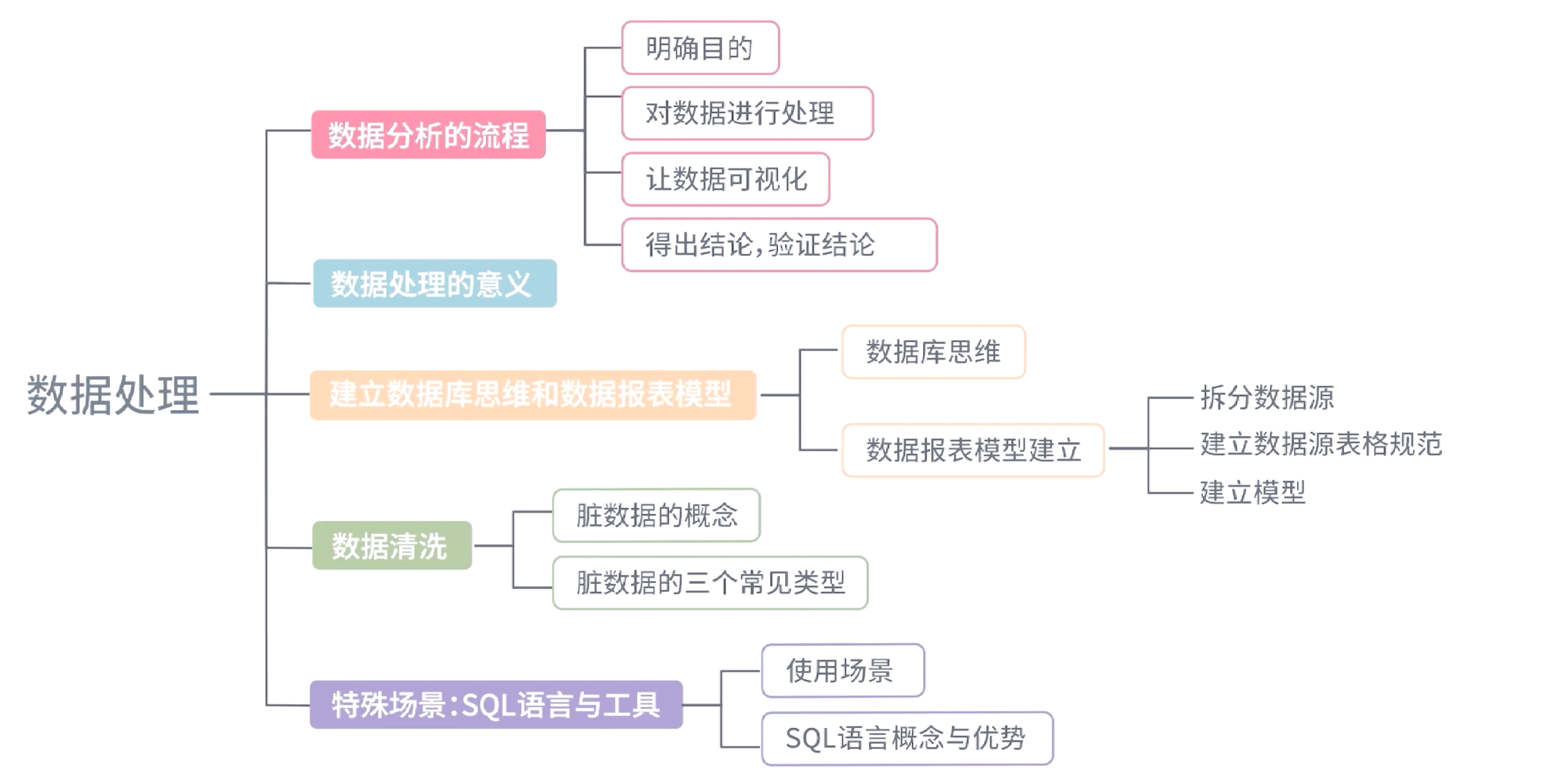
第三阶段:数据预处理与清洗
这是提升数据质量的关键步骤,常被称为“数据打磨”。主要任务包括:
- 数据清洗:处理缺失值、异常值、重复记录和格式不一致问题。
- 数据转换:进行标准化、归一化、离散化等操作,使数据适应分析模型。
- 数据集成与融合:将来自不同源的数据进行关联和合并,形成统一视图。
此阶段耗费大量精力,但“垃圾进,垃圾出”,高质量的数据是后续所有分析可靠性的基石。
第四阶段:数据计算与分析
在此阶段,数据被转化为信息和洞察。根据处理时效性,可分为:
- 批处理:对静态数据集进行离线、高吞吐量的计算,常用框架如Apache Spark、Flink(批模式)。适用于不追求实时性的历史数据分析、报表生成。
- 流处理:对连续不断的数据流进行实时或近实时计算,框架如Apache Flink、Storm、Kafka Streams。适用于监控、实时推荐、欺诈检测等场景。
分析手段涵盖描述性分析(发生了什么)、诊断性分析(为何发生)、预测性分析(将会发生什么)和规范性分析(应该采取什么行动),涉及统计分析、机器学习、数据挖掘等多种技术。
第五阶段:数据可视化与探索
分析结果需要通过直观的方式呈现,以辅助人类理解。数据可视化工具(如Tableau、Power BI、Superset)将复杂的数字和关系转化为图表、仪表盘和故事线。交互式数据探索允许分析师通过下钻、筛选等操作,从不同角度和粒度动态探查数据,发现潜在的模式和异常。
第六阶段:建模、应用与部署
当分析目标指向预测或自动化决策时,需要构建和训练模型(如机器学习模型)。流程包括:特征工程、模型选择、训练、评估与调优。一个成功的模型需要被部署到生产环境,集成到业务应用程序或服务中,以API、嵌入式模块等形式提供持续的服务,实现数据价值的最终产品化。
第七阶段:结论验证与流程闭环
这是确保整个数据处理流程科学、可靠的最后防线,也是常常被忽视的一环。
- 结果可重复性:确保在相同的数据和流程下,能够复现分析结论。
- 统计显著性检验:对于从数据中得出的模式或差异,使用统计方法检验其是否显著,而非随机波动。
- 业务合理性验证:数据结论必须与业务逻辑和领域知识交叉验证。一个统计上显著的发现,如果业务上无法解释,可能需要重新审视数据或方法。
- A/B测试与反馈循环:对于基于数据结论提出的策略或模型变更,通过A/B测试等方法在受控环境下验证其实际效果。将线上真实反馈数据重新收集,形成闭环,用于监控模型性能、发现数据漂移,并触发模型的迭代更新或流程的优化。
****
大数据处理并非一蹴而就的单一动作,而是一个从物理世界到数字世界,再从数字洞察反馈回物理实践的循环迭代工程。每个阶段都环环相扣,缺一不可。从零开始的数据采集到严谨的结论验证,这条完整链路不仅关乎技术实现,更体现了数据驱动的科学方法论:以数据为始,以验证为终,在持续的循环中逼近真相、创造价值。掌握全流程,方能真正驾驭大数据的力量。