在数字经济的浪潮下,数据已成为核心生产要素。构建一个清晰、健壮且可扩展的大数据技术体系,是释放数据价值、驱动业务智能化的基石。本文将以数据处理为核心线索,串联起技术架构、人工智能集成、业务与产品视图,并为您呈现一套精品的通用架构模版,以勾勒大数据从采集到赋能的全景图。
一、核心基石:数据处理流程图
数据处理是任何大数据系统的血脉。一个标准的数据处理流程通常遵循“采集-存储-计算-应用”的管道模型。
- 数据采集:通过日志埋点、传感器、数据库同步(CDC)、消息队列(如Kafka)等方式,从业务系统、物联网设备、外部API等多源异构数据源实时或批量获取数据。
- 数据存储:数据被摄入后,根据其热度和结构,分层存储于不同的系统中。例如,原始数据存入分布式文件系统(如HDFS)或对象存储(如S3);经过清洗和初步处理的数据存入数据湖(Data Lake);为高频分析优化的数据则进入数据仓库(如ClickHouse, Snowflake)或实时数仓。
- 数据处理与计算:这是核心环节,包含批处理(使用Spark, Flink Batch)、流处理(使用Flink, Spark Streaming)和交互式查询(使用Presto, Impala)。在此阶段,数据经过清洗、转换、聚合、关联,最终形成主题明确、质量可信的数据模型。
- 数据服务与应用:处理后的数据通过API、数据集市、BI报表、或直接写入业务数据库等方式,服务于上游的数据分析、机器学习、可视化应用和业务系统。
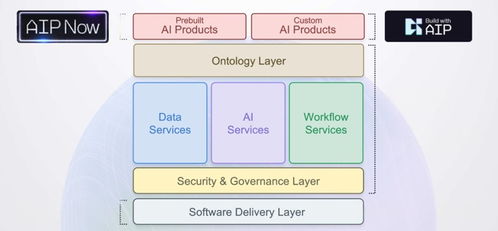
二、能力支撑:大数据技术架构图
技术架构是实现上述流程的物理与逻辑蓝图。一个典型的Lambda或Kappa架构是其代表。
批处理层:负责处理海量历史数据,保证计算的准确性和全面性,通常由Hadoop生态(HDFS, MapReduce, Hive)或Spark为核心构建。
速度层/流处理层:负责处理实时数据流,提供低延迟的洞察,核心是Flink、Spark Streaming或Storm等流计算引擎。
* 服务层:将批流合一的结果数据以低延迟的方式提供服务,可能涉及OLAP引擎、缓存(如Redis)和微服务API网关。
整个架构运行在资源管理层(如Kubernetes, YARN)之上,并由统一的数据治理、运维监控和安全管控平台进行管理和保障。
三、智能内核:人工智能模版架构图
大数据为AI提供燃料,AI则为大数据挖掘深层价值。一个集成AI的大数据架构通常包含:
- 数据层:即上述大数据处理流程的产出,为AI提供高质量的训练与推理数据。
- 算法与模型层:包含机器学习平台(如MLflow)、深度学习框架(如TensorFlow, PyTorch)和模型仓库,支持从特征工程、模型训练、评估到部署的全生命周期管理。
- 推理服务层:将训练好的模型封装为可扩展的API服务(常通过Docker容器化),无缝嵌入到实时数据流或在线业务系统中,实现实时预测与智能决策。
四、价值导向:大数据业务架构图与产品架构图
技术最终服务于业务。
- 业务架构图:从业务视角出发,描绘数据如何支撑各个业务域(如营销、风控、供应链)的目标。它明确了数据需求方、数据产生的业务活动、以及数据驱动的关键业务决策点,是连接技术与业务的桥梁。
- 产品架构图:从产品交付视角,定义面向用户(如数据分析师、业务人员、开发者)的数据产品形态。例如,它可以是一个包含数据门户、自助分析工具、报表平台、API市场和数据科学工作台的一体化数据中台产品套件。
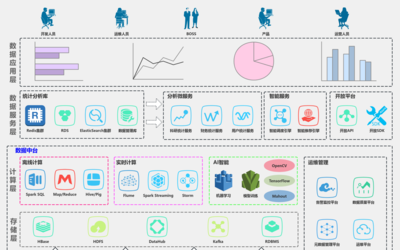
五、整合视图:通用大数据架构图模版(精品模版)
综合以上各点,一套精品通用大数据架构模版应具备以下分层与核心组件:
【数据源层】:内部业务库、日志、IoT设备、第三方数据。
【数据摄入与集成层】:Sqoop, Flume, Kafka, CDC工具。
【存储与计算基础设施层】:
* 存储:对象存储/数据湖(原始数据)、数据仓库(模型化数据)、NoSQL(非结构化/缓存)。
- 计算:统一资源管理(K8s/YARN)、批处理引擎(Spark)、流处理引擎(Flink)、OLAP引擎(Doris/StarRocks)。
【数据管理与治理层】:统一元数据管理、数据质量监控、数据安全与隐私合规、主数据管理。
【数据资产与服务层】:
* 资产化:主题数据模型、指标系统、特征平台。
- 服务化:统一数据服务API网关、BI报表平台、数据科学平台(含AI/ML)。
【应用与消费层】:精准营销、风险控制、智能运维、用户画像等具体业务应用。
该模版强调了“流批一体”的计算趋势、“湖仓一体”的存储趋势,以及“数据即服务”的交付趋势。通过清晰的分层和模块化设计,它既能保持各层间的解耦与灵活性,又能确保数据流在全栈中的高效、有序流动,最终将原始数据转化为驱动业务增长与创新的智慧能量。